Compute Architecture and Scheduling
Introduction
Hi there! The blog post aims to share a high-level overview of the computing architecture. It then explores the concepts of resource alignment, block scheduling, and occupancy. It also discusses thread scheduling, latency tolerance, control divergence, and synchronization.
This blog post is written while reading the fourth chapter, Compute Architecture and Scheduling, of the incredible book “Programming Massively Parallel Processors: A Hands-on Approach1” by Wen-mei W. Hwu, David B. Kirk, and Izzat El Hajj.
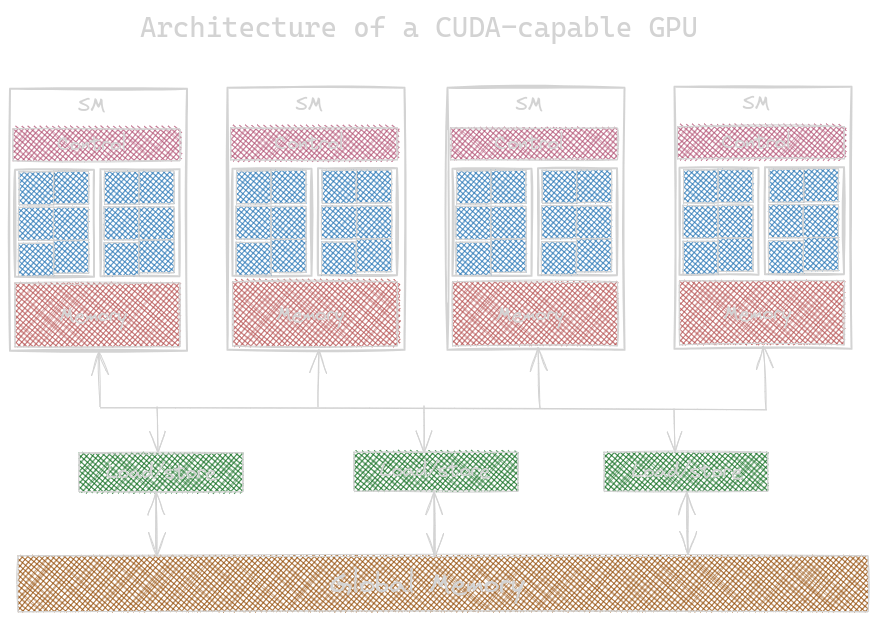
Architecture of a modern GPU
A CUDA-capable GPU is organized into an array of highly threaded steaming microprocessors (SMs), each SM having several processing units called CUDA cores.
Block Scheduling
When a kernel is launched, the CUDA runtime system launches a grid of threads that execute the kernel code. These threads are assigned to SMs on a block-by-block basis. This assignment guarantees that threads in the same block are scheduled simultaneously and that there is no interaction between threads of different blocks. The runtime system maintains the list of blocks needed to execute and assigns new blocks to SMs.
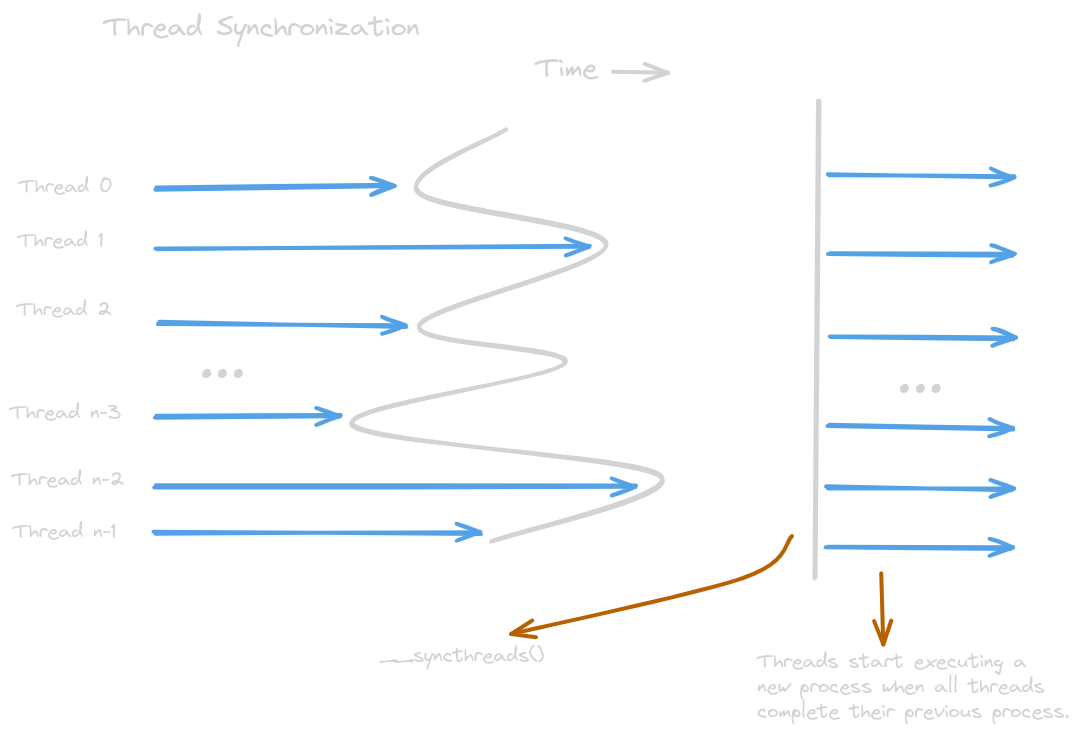
Synchronization and Transparent Scalability
Threads in the same block coordinate activities using the
barrier synchronization function __syncthreads(). Barrier
synchronization is a method to coordinate the activities of multiple
threads such that a new process will start only if the activities of
all the threads in a block are completed. It’s the programmer’s
responsibility to ensure that each thread has all the required
resources needed for the execution. Otherwise, it’ll lead to a
deadlock; that is, the thread will never be able to complete
the execution. This will lead to other threads waiting for the
execution forever, and the programmer will never know about it.
Note that the block can begin new execution only if the runtime
system has secured all the resources needed for threads to complete
its process. The blocks can be executed in different orders.
This allows transparent scalability across different devices.
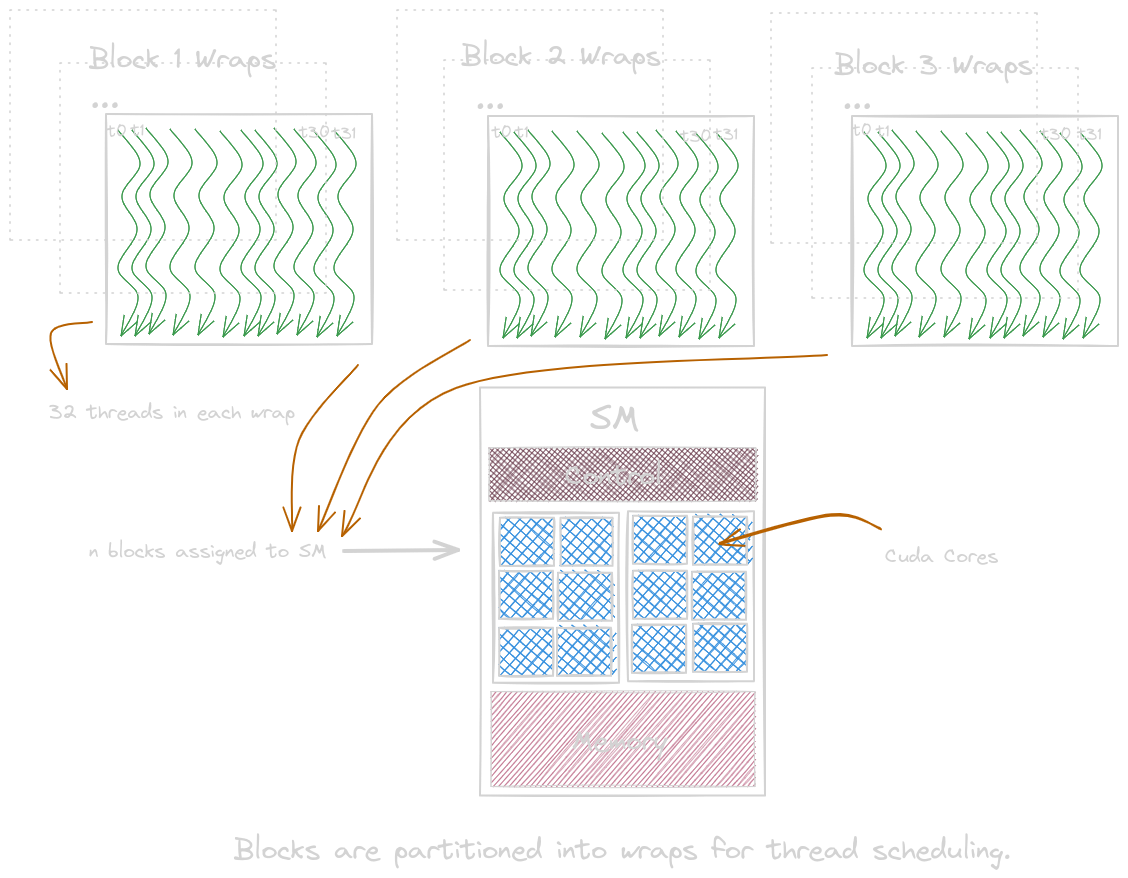
Wraps and SIMD Hardware
Once the blocks are assigned to the SM, they are divided into 32 thread each units called wraps. Thread scheduling must be handled with hardware-specific implementations. Each block can have multiple units of wraps. If a block does not have a number of threads as a multiple of 32, it will be padded with inactive threads. A block with multiple thread dimensions will be linearized into a row-major/column-major layout before being divided into wraps. One instruction is fetched and is executed by multiple threads in wraps.
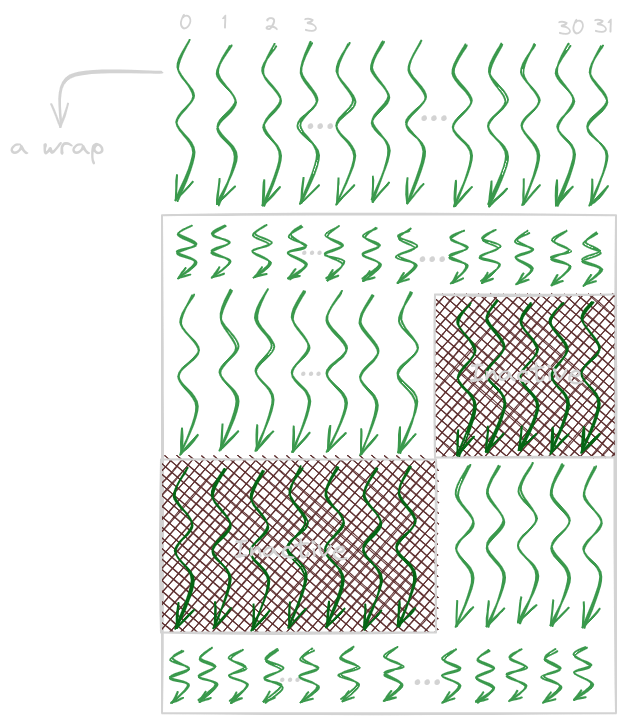
Control Divergence
Threads show control divergence when they follow different
execution paths within the same wrap. The hardware needs to make
an extra pass to make thread their own decision; the resources
are consumed for inactive threads. The performance impact of
control divergence decreases with the increase in the number of
data to be processed. To synchronize threads in a wrap, we use __syncwrap().
Wrap Scheduling and Latency Tolerance
More threads are assigned to an SM than there are cores in the SM to tolerate long-latency operations such as global memory accesses. So when an instruction needs to be executed by the wraps, the process does not need to wait; the threads waiting for their turn get the chance to be executed first. This mechanism of filling the latency time of operations from some threads with work with the other thread is called latency hiding. The wraps that are ready for execution do not add any wasted time. This is known as zero-overhead thread scheduling. This is why GPUs dedicate more area to floating-point operations than to cache memory.
Resource Partitioning and Occupancy
The ratio of the number of wraps assigned to an SM to the maximum number it supports is called occupancy. The resources are dynamically partitioned across threads to support their execution. This prevents resource underutilization and preserves its limitations. Let’s take an example:
Example 1: maximum occupancy
block_size = 64;
number of blocks per SM = 32;
number of threads assigned to each SM = 64 x 32 = 2048
occupancy = number of threads assigned / maximum number it supports = 2048 / 2048 = 1
Example 2
block_size = 32
number of blocks = 32
number of threads in each SM = 32 x 32 = 1024
occupancy = number of threads assigned / maximum number it supports = 1024 / 2048 = 0.5
When the maximum number of threads per block is not divisible by the block size, occupancy is negatively affected. We should also note the register resource limitations on occupancy.
Where to Go Next?
I hope you enjoyed reading this blog post! If you have any questions or suggestions, please feel free to drop a comment or reach out to me. I’d love to hear from you!
This post is part of an ongoing series on CUDA programming. I plan to continue this series and keep things exciting. Check out the rest of my CUDA blog series:
- Introduction to Parallel Programming and CPU-GPU Architectures
- Multidimensional Grids and Data
- Compute Architecture and Scheduling
- Memory Architecture and Data Locality
- Performance Considerations
- Convolution
- Stencil
- Parallel Histogram
- Reduction
Stay tuned for more!
Resources & References
1. Wen-mei W. Hwu, David B. Kirk, Izzat El Hajj, Programming Massively Parallel Processors: A Hands-on Approach, 4th edition, United States: Katey Birtcher; 2022
2 Intro to Compute and Memory Architecture YouTube by Thomas Viehmann, Feb 2024
3. I used Excalidraw to draw the kernels.
Let me know what you think of this article on Twitter @khushi__411 or leave a comment below!