Woohoo, GSoC'22 soon!
Heyoo!! I’m happy to share that I was selected for Google Summer of Code 2022. I’ll be working on the project CuPy under the umbrella of the NumFOCUS organization. Wowza, here’s my acceptance letter from Google:
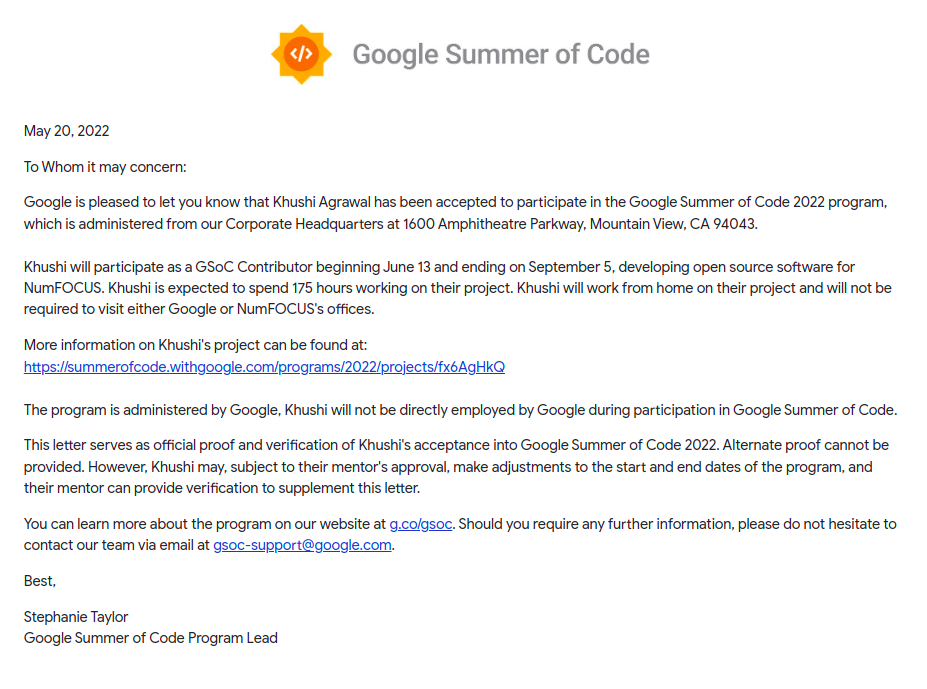
My project is mentored by Masayuki Takagi and with the support of the CuPy team!
I aim to introduce the interpolate module in CuPy and
enhance the scope of special and stats modules in CuPy.
If you want to know more about my project, you can
visit the GSoC Link.
This internship is special to me because GSoC was the first thing I aimed to achieve even before entering college. I want to complete my task on time, and I’m looking forward to learning and exploring new things & exciting experiences along with the guidance of so many talented people I’ll be connecting with throughout the GSoC timeline.
In the upcoming part of this blog post, I’ll be sharing about:
- My Journey & Motivation
- About the CuPy
- Community Bonding Period
- Acknowledgement
My Journey & Motivation
This is the most exciting part of the blog post! :p
Let’s start from the beginning; a few months back, I was working on a project neural-lib, a simple neural network library coded from scratch and implemented in PyTorch Python. After preparing a draft, I requested Kshitij for his reviews. And I believe that was a turning point. He said:
I thought about the project a bit and if you want to give a GPU and Autograd support to your project, then using CuPy makes sense.
I was fascinated to know about CuPy. I did hear about CuPy during my past internship at Quansight. And this intensified my curiosity to learn more about it. I stumbled upon CuPy’s GitHub repository. I checked various issues and previous PRs.
Woohoo, I was so lucky! I saw Kenichi
created an issue tracker for Implementing all NumPy
APIs in CuPy #6078.
Thanks, Kenichi, the first person from whom I learned to
write tests, about CuPy’s codebase, and much more.
I was very much intended to work on it. The next day
I sent my first PR in CuPy, implementing cupy.asfarray!
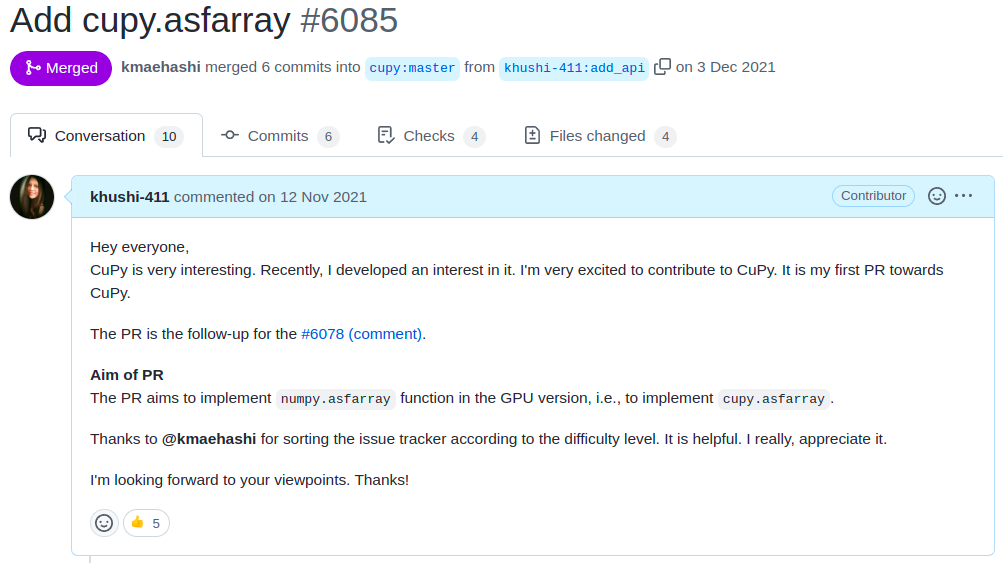
It was an interesting PR; I learned many things, though I believe it is a bit of embarrassing PR for me right now :o. I continued contributing to CuPy, working on CuPy’s coverage of NumPy functions. While contributing, I developed a keen interest in working on project CuPy for this year’s GSoC!
The time to start preparing for GSoC!! I stumbled on
the wiki page from CuPy’s 2022
Project ideas.
Out of the three proposed projects, two of them fascinated me!
The project CuPy coverage of NumPy/SciPy functions and
Enhance CuPy JIT interface immediately attracted me.
After researching more about the topics, I decided to go for the first project since I had more ideas and surety about it. I selected the coverage of SciPy functions as my GSoC project. You can learn more about my project in my proposal.
After submitting my proposal, I felt relaxed and confident about my application. Cheers
About the CuPy
![]()
Credits official website:
CuPy is an open-source array library for GPU-accelerated computing with Python. CuPy utilizes CUDA Toolkit libraries including cuBLAS, cuRAND, cuSOLVER, cuSPARSE, cuFFT, cuDNN and NCCL to make full use of the GPU architecture. CuPy speeds up some operations more than 100X.
From the great description above by CuPy Team, we comprehend CuPy is an edge-cutting technology mainly used for scientific computing, data science, research, and many more. It supports CUDA C++ features and presents highly optimized implementations to the users at more than 100x speed! Hence, user friendly! I’ll be covering more about the optimization techniques used by CuPy in my upcoming blog posts. Stay tuned!
Community Bonding Period
First of all, thanks to my mentor, @takagi, and the team for your warm welcome and for finding my proposal relevant to work with you all!
To the audience: The community bonding period is the first period of the GSoC timeline, where mentors and students interact to discuss their projects and ways they’ll connect in the upcoming month.
My mentor clearly explained the expectations of three organizations relating to my project. We discussed that we’d connect via Gitter chat room and GitHub. (P.S. If you want to join the public cupy community channel, you can use this link).
We started our project by discussing the order of the implementation we will follow for the upcoming months. Initially, we planned to work on BarycentricInterpolator, special, stats functions, and then one more interpolate function. But later, we switched to implementing special and stats functions first, then the interpolate interpolating module this was finalized according to the user demand. Some of the things we discussed during these two weeks, in brief, are mentioned below. I’ll divide this into three parts:
-
Implementing BarycentricInterpolator: I always wanted to introduce a module; interpolate is my first. To the readers of this blog post,
BarycentricInterpolatoris used to construct a polynomial from the given points and evaluate it. The numerical stability of this interpolate function is still a challenging thing for us! We discussed the places we will need to implement the algorithm in GPU and identified areas that are okay with executing it in CPU. This was decided by the number of points given to the function as an input. Many things still need to work on it for the upcoming months. My mentor suggested going through Berrut and Trefethen’s paper. I thoroughly read that paper. -
Implementing logsumexp, softmax, and log_softmax: Wow, we now started to work on special functions! To begin discussing, I prepared an introductory slide describing the ideas to implement these functions according to my understanding. We discussed how we could optimize our implementation in CuPy. We are implementing
ReductionKernelsto do so. We discussed how these relate tofunctools.reduce()in Python. I’ll write another blog post describing more about it. -
Implementing log_ndtr: I created a
cupy._core.ufuncto implementlog_ndtr. One thing that fascinated me about this is due to higher numerical precision; we changed the algorithm instead of just implementing using the formula:log(ndtr)as SciPy did. We (the team and I) will be discussing the implementation soon.
Thanks, Takagi! This was an awesome experience of the community bonding period with you and the CuPy team! So excited to get into it. A lot to learn in the upcoming months <3
Also, please note that this is just the “Woohoo, GSoC’22 soon!” post where I shared my exciting experiences. I’ll share more about the concepts I learned in my upcoming posts. Catch you there :)
Acknowledgement
I appreciate the time and guidance my mentors and family have put into me.
Thanks to the CuPy team @asi1024, @emcastillo, @kmaehashi, @leofang, @takagi, and @toslunar for really quick reviews and for sharing your knowledge with me via reviewing all my PRs and for reviewing my proposal guiding it to shape well.
Thanks to @kshitij12345 for helping me select the functions, for all your valuable viewpoints, and for all the informative shares for writing the proposal.
Special thanks to my family, my inspiration! who always supported me and helped me to make this happen. <3
Thank you so much!
Let me know what you think of this article on Twitter @khushi__411 or leave a comment below!